

A new ERP near PLM layer
Today we illuminate why a new ERP near PLM layer ist crystallizing.
The shift from Select to Order (STO) and Engineering to Order (ETO) to Configure to Order (CTO) and CTO+ is changing the industry. Realizing the CTO and CTO+ process patterns requires a new way of thinking about companies and their main processes.
Why is this so?
This can be explained by the use of different types of data. Traditionally, a distinction is made between master data and transaction data.
Master data is a prerequisite for the IT-System (ERP) supported and automated handling of the (main) processes in the company which then generate the transaction data.
These can be divided into sections and assigned to the current system classes. CRM would then be Lead to Order, ERP Order to Cash, Purchase to Pay and Plan to Produce, with MES also covering part of this process.
For a long time, master data was seen as data that did not change over a longer period of time. This classic view is no longer sustainable today. It is important to understand that all master data is subject to further development, changes and thus to a lifecycle. The dynamics of rapid changes of all types of master data has accelerated in recent years. Product data has a special position here. The dynamics of product data change through CTO+ approaches exceeds anything that has been seen before.
With CTO and CTO+, high-frequency changes in master data affect the operational handling of lead-to-order and order-to-cash processes. The order-specific changes in product data must be fed into the operational processes quickly, directly and in a revision-correct manner. However, this is only one aspect. In addition, the control parameters for the operational control of the quantities and value flows of the variant must be adapted accordingly. In the case of internationally active companies, this must also be able to take place worldwide under conditions such as local sourcing and local customizing.
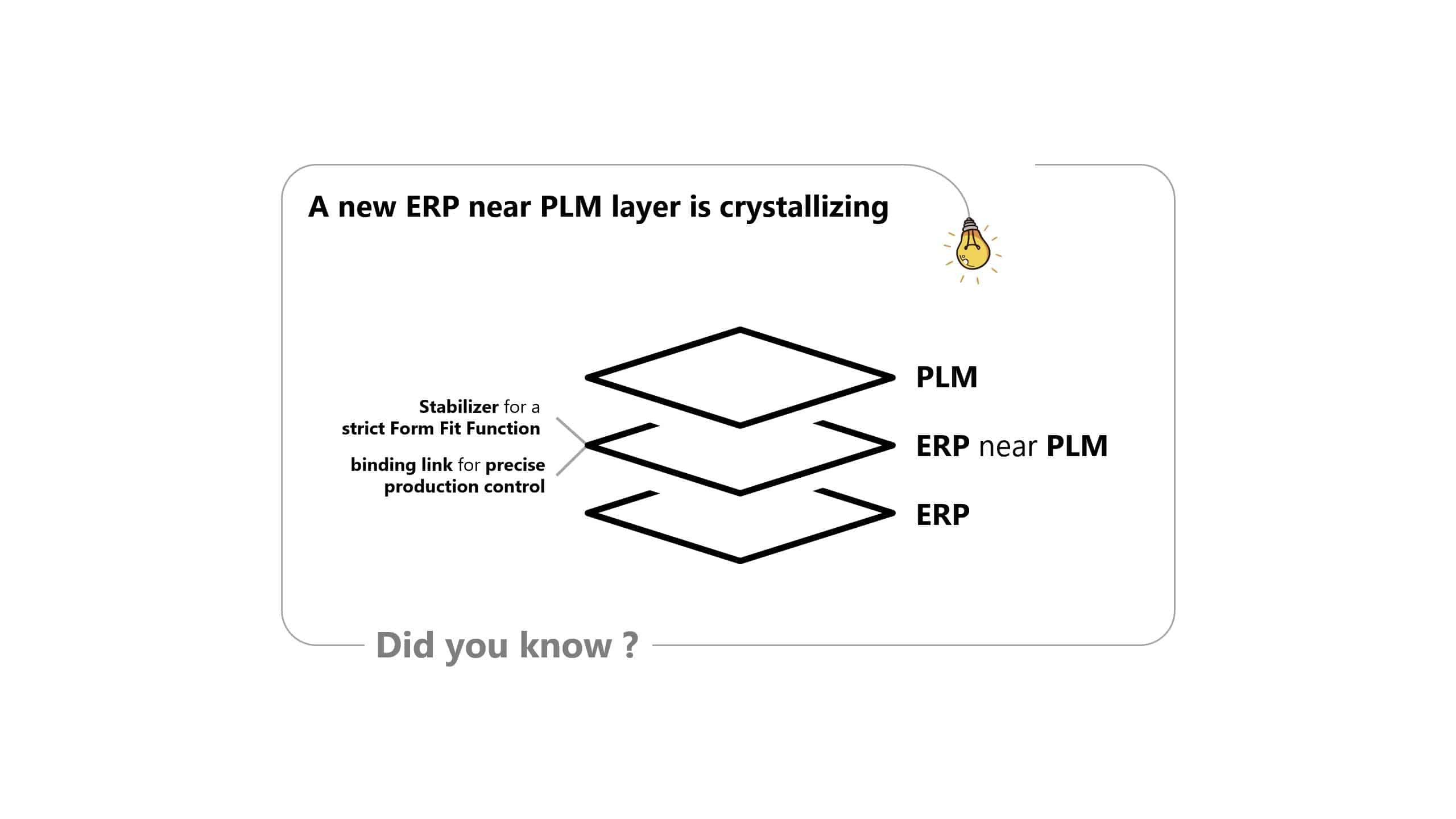
This will necessitate a new ERP near PLM layer. It has the following main tasks
- control of the ah hoc adaptation development in the quote and order phase
- subtractive configuration of the concrete variant down to the local sourcing and customizing level
- case-by-case additive configuration (resp. compilation) of the components to the overall system (application)
- supply of the execution processes with adapted control parameters for quantity and value control in the supply chain
- supply of the local operation technology (OT) with order-related technical control parameters
- audit-proof traceability of order-specific changes in the product data
- case-by-case supply of the change in the product platform (150% EBOM’s)
- Stabilizer for a strict Form Fit Function
Briefly a few insights to point 8. Revisions in PLM systems are often also used to keep very similar implementations (material classically spoken) together. Therefore, a very strict FFF is avoided. An ERP near PLM layer, needs a bracketing function so that similar implementations can be kept together. Then a very strict FFF can be adhered to and implementations that were previously held together via revisions can be made explicit in individual implementations.
If one looks now at available PLM systems of the classic PLM Vendors and makes itself conscious that these do not know the order or have order objects, becomes clear that all 8-Tasks are not covered.
Since the vendors have expanded their data models in recent years, task 1, 3 and 6 can be implemented today with a little effort and some compromises.
For the other task, there are no functionality in the classic PLM systems and no data models that could enable it (with strong customizing and some compromises it might be possible).
However, the new layer does not need to be an own IT system. It can be integrated into existing systems or realized in the form of a composable cloud architecture. It is only important to specify how it should work and then implement it.
It will be exciting to see how SAP and Siemens position each other in this regard. It will also be interesting to see how the other vendors, especially the smaller ones, position themselves.
If you want to know how this scenario can be solved, how a ERP near PLM works and how you can implement it today, then ask us at STZ-RIM.
Just my thoughts. What do you think?

